Please visit Search Engine Land for the full article.
from Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing https://ift.tt/345hFgE
This blog is for latest SEO Updates and SEO Articles & SEO Videos Learn SEO Easy in Hindi/Urdu Language
Posted by rjonesx.
One of the most difficult decisions to make in any field is to consciously choose to miss a deadline. Over the last several months, a team of some of the brightest engineers, data scientists, project managers, editors, and marketers have worked towards a release date of the new Page Authority (PA) on September 30, 2020. The new model is exceptional in nearly every way to the current PA, but our last quality control measure revealed an anomaly that we could not ignore.
As a result, we’ve made the tough decision to delay the launch of Page Authority 2.0. So, let me take a moment to retrace our steps as to how we got here, where that leaves us, and how we intend to proceed.
Historically, Moz has used the same method over and over again to build a Page Authority model (as well as Domain Authority). This model's advantage was its simplicity, but it left much to be desired.
Previous Page Authority models trained against SERPs, trying to predict whether one URL would rank over another, based on a set of link metrics calculated from the Link Explorer backlink index. A key issue with this type of model was that it couldn’t meaningfully address the maximum strength of a particular set of link metrics.
For example, imagine the most powerful URLs on the Internet in terms of links: the homepages of Google, Youtube, Facebook, or the share URLs of followed social network buttons. There are no SERPs that pit these URLs against one another. Instead, these extremely powerful URLs often rank #1 followed by pages with dramatically lower metrics. Imagine if Michael Jordan, Kobe Bryant, and Lebron James each scrimaged one-on-one against high school players. Each would win every time. But we would have great difficulty extrapolating from those results whether Michael Jordan, Kobe Bryant, or Lebron James would win in one-on-one contests against each other.
When tasked with revisiting Domain Authority, we ultimately chose a model with which we had a great deal of experience: the original SERPs training method (although with a number of tweaks). With Page Authority, we decided to go with a different training method altogether by predicting which page would have more total organic traffic. This model presented several promising qualities like being able to compare URLs that don’t occur on the same SERP, but also presented other difficulties, like a page having high link equity but simply being in an infrequently-searched topic area. We addressed many of these concerns, such as enhancing the training set, to account for competitiveness using a non-link metric.
The results were — and are — very promising.
First, the new model obviously predicted the likelihood that one page would have more valuable organic traffic than another. This was expected, because the new model was directed at this particular goal, while the current Page Authority merely attempted to predict whether one page would rank over another.

Second, we found that the new model predicted whether one page would rank over another better than the previous Page Authority. This was especially pleasing, as it laid to rest many of our concerns that the new model would underperform on old quality controls due to the new training model.
How much better is the new model at predicting SERPs than the current PA? At every interval — all the way down to position 4 vs 5 — the new model tied or out-performs the current model. It never lost.

Everything was looking great. We then started analyzing outliers. I like to call this the “does anything look stupid?” test. Machine learning makes mistakes, just as humans can, but humans tend to make mistakes in a very particular manner. When a human makes a mistake, we often understand exactly why the mistake was made. This isn’t the case for ML, especially Neural Nets; we pulled URLs with high Page Authorities under the new model that happened to have zero organic traffic, and included them in the training set to learn for those errors. We quickly saw bizarre 90+ PAs drop down to much more reasonable 60s and 70s… another win.
We were down to one last test.
Some of the most popular keywords on the web are navigational. People search Google for Facebook, Youtube, and even Google itself. These keywords are searched an astronomical number of times relative to other keywords. Subsequently, a handful of highly powerful brands can have an enormous impact on a model that looks at total search volume as part of its core training target.
The last test involves comparing the current Page Authority to the new Page Authority, in order to determine if there are any bizarre outliers (where PA shifted dramatically and without obvious reason). First, let’s look at a simple comparison of the LOG of Linking Root Domains compared to the Page Authority.
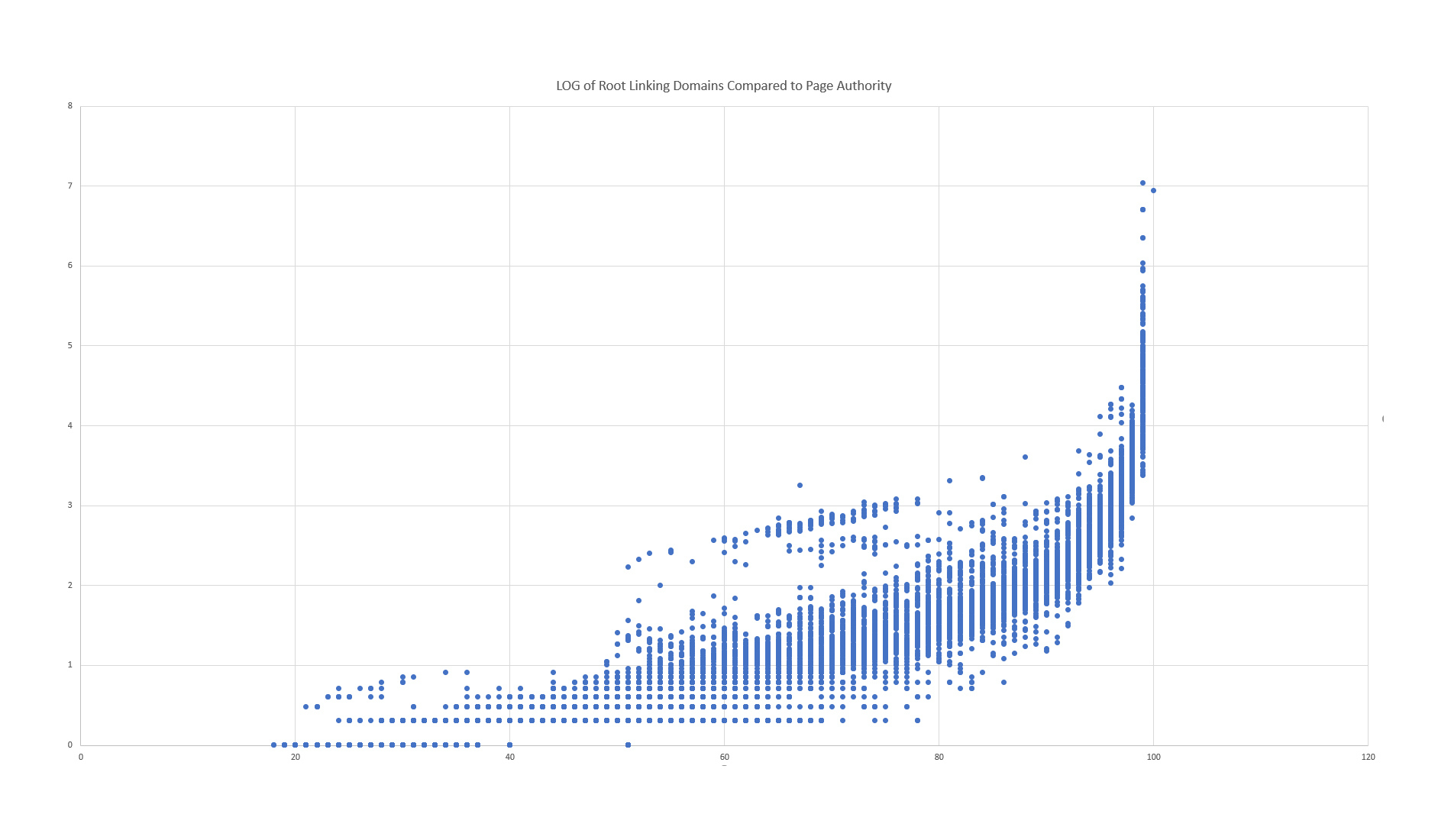
Not too shabby. We see a generally positive correlation between Linking Root Domains and Page Authority. But can you spot the oddities? Go ahead and take a minute…
There are two anomalies that stand out in this chart:
Here is a visualization that will help draw out these anomalies:
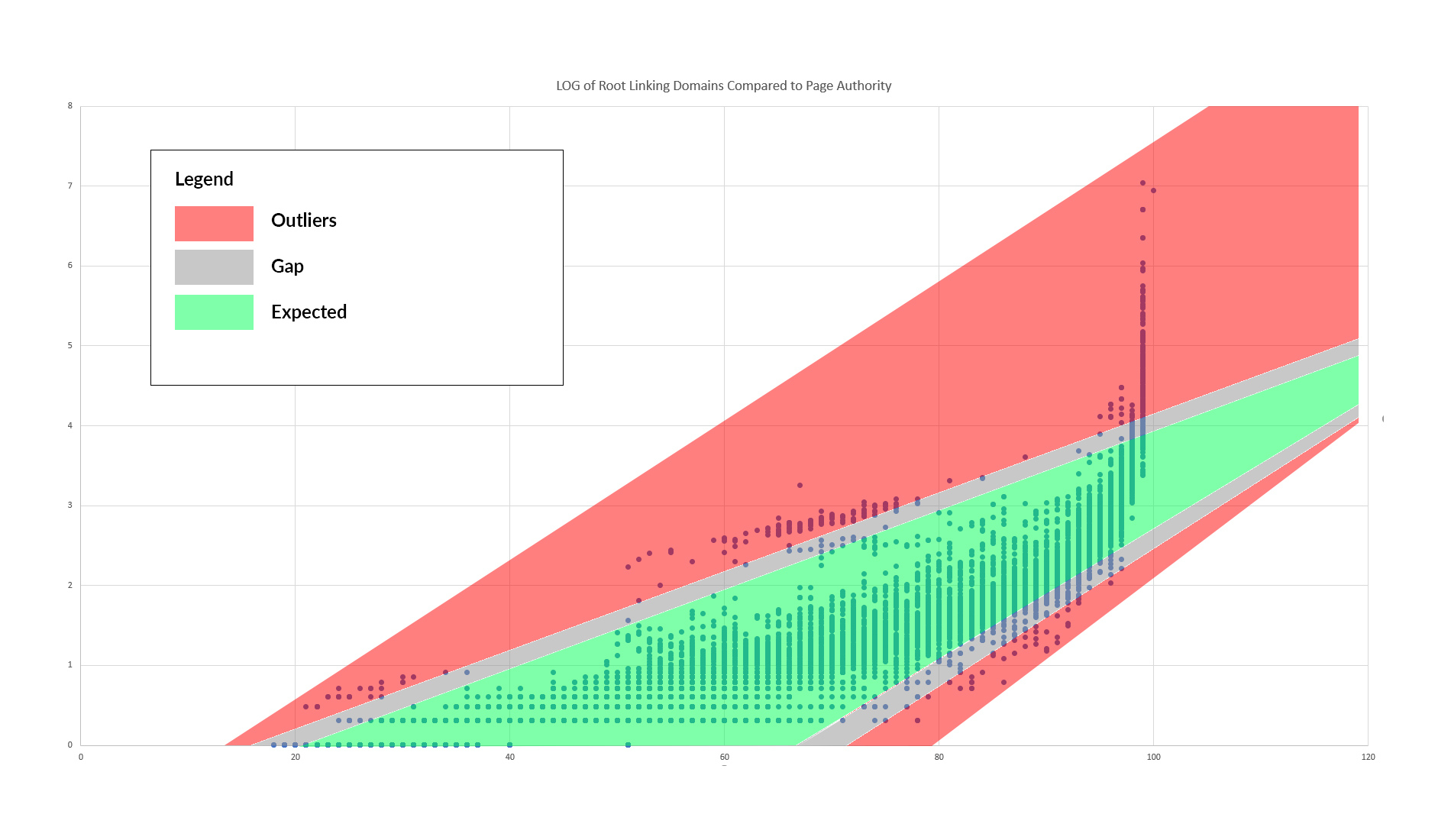
The gray spaces between the green and red represent this odd gap between the bulk of the distribution and the outliers. The outliers (in red) tend to clump together, especially above the main distribution. And, of course, we can see the poor distribution at the top of PA 99s.
Bear in mind that these issues are not sufficient to make the new Page Authority model less accurate than the current model. However, upon further examination, we found that the errors the model did produce were significant enough that they could adversely influence the decisions of our customers. It’s better to have a model that is off by a little everywhere (because the adjustments SEOs make are not incredibly fine-tuned) than it is to have a model that is right mostly everywhere but bizarrely wrong in a limited number of cases.
Luckily, we’re fairly confident as to what the problem is. It seems that homepage PAs are disproportionately inflated, and that the likely culprit is the training set. We can’t be certain this is the cause until we complete retraining, but it is a strong lead.
We are in good shape insofar as we have multiple candidate models that outperform the existing Page Authority. We’re at the point of bug squashing, not model building. However, we are not going to ship a new score until we are confident that it will steer our customers in the right direction. We are highly conscientious of the decisions our customers make based on our metrics, not just whether the metrics meet some statistical criteria.
Given all of this, we have decided to delay the launch of Page Authority 2.0. This will give us the necessary time to address these primary concerns and produce a stellar metric. Frustrating? Yes, but also necessary.
As always, we thank you for your patience, and we look forward to producing the best Page Authority metric we have ever released.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!